

Исследователи использовали простую текстовую задачу, чтобы показать, что современные языковые модели терпят неудачу, когда дело доходит до базовых логических выводов. При этом модели настаивают на неправильных ответах и переоценивают свои возможности.
Большая языковая модель (БЯМ — калька с англ. large language model, LLM) — это языковая модель, состоящая из нейронной сети со множеством параметров (обычно миллиарды весовых коэффициентов и более), обученной на большом количестве неразмеченного текста с использованием обучения без учителя. БЯМ появились примерно в 2018 году и хорошо справляются с широким спектром задач.
Используя простую текстовую задачу, исследователи из лаборатории искусственного интеллекта LAION, Суперкомпьютерного центра (Jülich, Германия) и других институтов, обнаружили серьёзные недостатки в логическом мышлении современных языковых моделей.
Задача представляет собой простую головоломку, которую могут решить большинство взрослых и, вероятно, даже дети младшего школьного возраста: “У Алисы есть N братьев и M сестёр. Сколько сестёр у брата Алисы?”.
Правильным ответом будет сложение М+1 (Алиса плюс её сёстры). Исследователи варьировали значения N и M, а также порядок братьев и сестёр в тексте.
Они загрузили головоломку в малые и большие языковые модели, такие как GPT-4, Claude, LLaMA, Mistral и Gemini, которые известны своими предположительно сильными способностями к логическому мышлению.
Результаты оказались неутешительными: большинство моделей не смогли решить задачу или решали её лишь от случая к случаю. Различные стратегии подсказок не изменили основной результат.
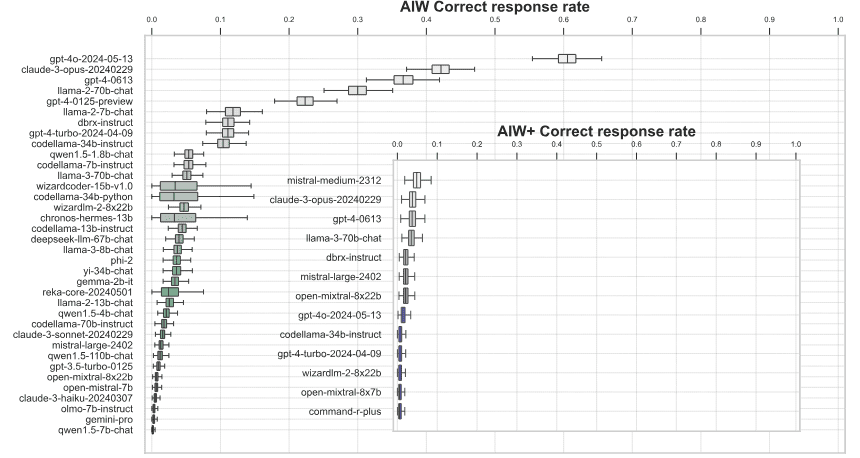
Только GPT-4 и Claude иногда могли найти правильный ответ и подкрепить его правильным объяснением. Но даже у них процент успеха сильно варьировался в зависимости от точной формулировки подсказки.
В целом, средний процент правильных ответов языковых моделей оказался ниже 50 процентов. Только GPT–4o показала результат выше среднего – 0,6 правильных ответов.

Материалы: The-decoder.com (Matthias Bastian)